Summary of work so far and preliminary results
Our project involves working with the existing codebase of the Terrier database and improving the performance of the Scan() function. Our first step was to setup the database locally and ensure that we can replicate its expected performance on our local machines. Subsequently, we needed to write benchmarks to highlight the problem that we are trying to solve. The preliminary benchmarks we created involve populating a dummy database instance with 10 million data elements and then proceeding to Scan() through them.
In order to evaluate and benchmark the performance of multiple threads, we write different benchmarks using (incrementally) more threads. This would allow us to see how the workload scales across the number of threads. Since we our workload involves scanning a list of database blocks, the task is inherently sequential. One way to distribute the workload could be to reduce the size of the items in the database proportional to the number of threads and each thread scans the entire list. While this would ensure the number of elements scanned is the same as the case of a single thread, a more intuitive approach is allowing each thread to Scan() through the entire list. As a result, a benchmark running 4 threads would be doing 4x as much work as that running on a single thread. Our task then becomes reducing the run-time for each thread to be the same as a scenario with only a single thread, i.e, achieve a 100% work efficiency. The baseline numbers for the project are below. The numbers provided are averaged over 5 runs of the benchmarks.
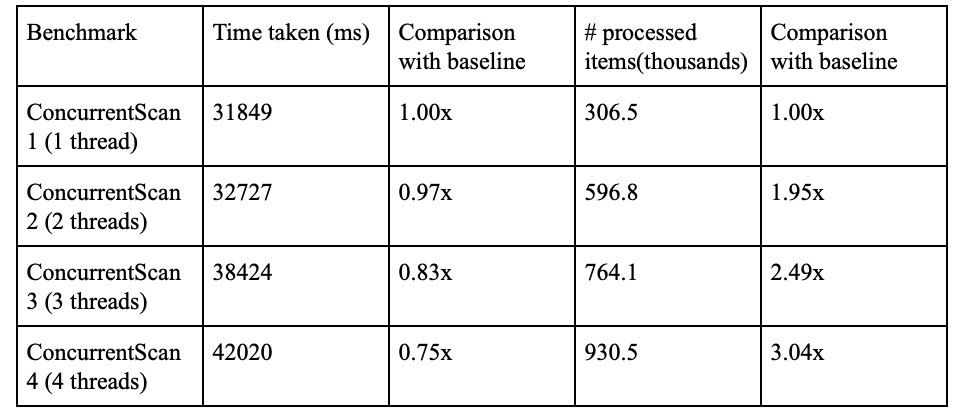
From the results above, we find that while increasing the number of threads results into more work done, we observe that the efficiency is not ideal. In other words, doing 4x the amount of work requires more than the time needed by the baseline conditions, and we are able to process ~3x the number of items as opposed to the ideal circumstances where we would be processing 4x as many. As a result, we are successful in being able to highlight the concurrency overheads prevalent in the system at the moment.
Next, we try to highlight the source of these overheads. For the purpose of establishing an upper bound and to narrow down the location of these overheads, we remove a (concurrent) part of the workload and remove locks on the database iterator. This experiment would, ideally, reduce the time taken for each benchmark to be the same, i.e, it would remove the overhead associated with each of the concurrent executions since we remove the (contested) workload itself. The results are below:
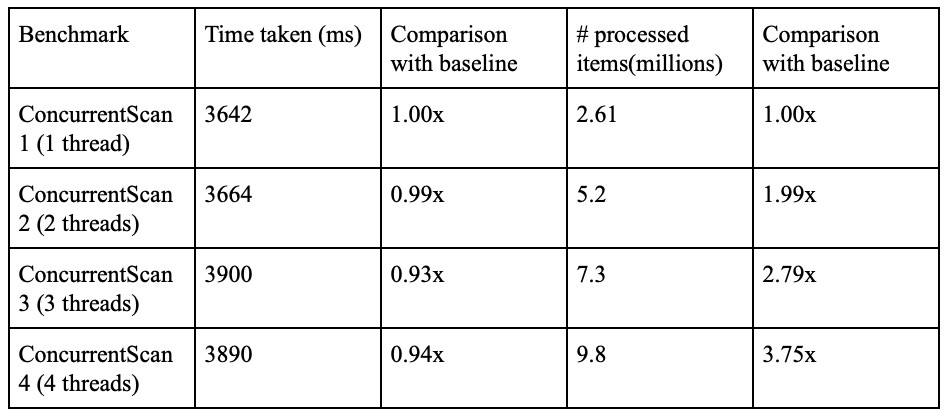
These results are a lot closer to the ideal circumstances in terms of the work efficiency and time taken by each benchmark. This shows that the overheads associated with the concurrent parts of the system as well as the locks associated with the database iterators introduce a large concurrency overhead which impacts the performance.
One of our proposed changes to the system included repositioning the iterator latch associated with incrementing the database iterator to another part of the function in an attempt to remove the overhead of unnecessary acquires. To establish an upper bound for the effectiveness of the function, we remove this latch entirely and run our benchmarks again. We find a small but positive effect on the results from the benchmark (table below).
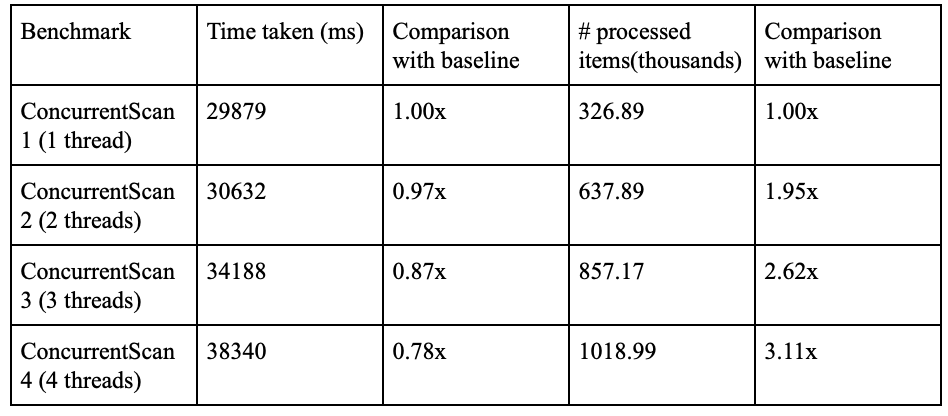
We then reposition the latch and repeat the same experiments. We find that while there is an improvement in performance, the improvement is a little worse than that in the table above. This is inline with our expectations since the above table is generated without a latch at all.
We do not, however, present the results from this method as a part of this report. After experimenting with the unittests present in the system, we find that there aren’t enough unit tests which test the concurrent read/insert functions that we are modifying. As a result, it is possible to introduce correctness issues via race conditions and still not be able to detect them. Thus, our task is now to first write such a test to validate our current (and future approaches). The updated schedule with this change is provided at the end of this report.
What do you plan to show at the poster session? Will it be a demo? Will it be a graph?
We will be presenting graphs which highlight the effectiveness of using multiple cores as opposed to the single core baseline performance. The metrics we use for these plots will include relative speedup and efficiency (in terms of number of processed items).